# 浅析 V8 引擎执行机制

JavaScript 做为编程界的宠儿,一直具有很大的用户群体,随着在服务端的使用(NodeJs),更是爆发了极强的生命力。随着 Web 相关技术的发展,JavaScript 所要承担的工作也越来越多,早就超越了“表单验证”的范畴,这就更需要快速的解析和执行 JavaScript 脚本。V8 引擎就是为解决这一问题而生,在 node 中也是采用该引擎来解析 JavaScript。
本文章主要梳理了 V8 引擎的执行机制相关内容,主要方便自己后期更加清晰的理解 JavaScript 内部执行机制,像是执行上下文、变量提升等相关内容。
# 一、认识什么是 JavaScript 引擎
在前面深入理解浏览器的执行机制以及工作原理的文章中说到,浏览器的内核主要由两个部分构成:
渲染引擎:负责解析 HTML 解析、布局、渲染等工作内容JS引擎:解析、执行 JavaScript 代码
JavaScript 做为一门高级编程语言,如果想要计算机识别需要将其转换成机器指令,JS 引擎就是将 JavaScript 转换成机器指令让计算机能够识别。比较常见的 JavaScript 引擎:
SpiderMonkey:第一款 JS 引擎,由 Brendan Eich(JavaScript 的作者)开发Chakra:微软开发,用于 IE 浏览器JavaScriptCore:Webkit 中的 JS 引擎,Apple 公司开发V8:Google开发的强大的 JS 引擎,也帮助 Chrome 从众多浏览器中脱颖而出
编程语言分为编译型语言和解释型语言两类,编译型语言在执行之前要先进行完全编译,而解释型语言一边编译一边执行,很明显解释型语言的执行速度是慢于编译型语言的。
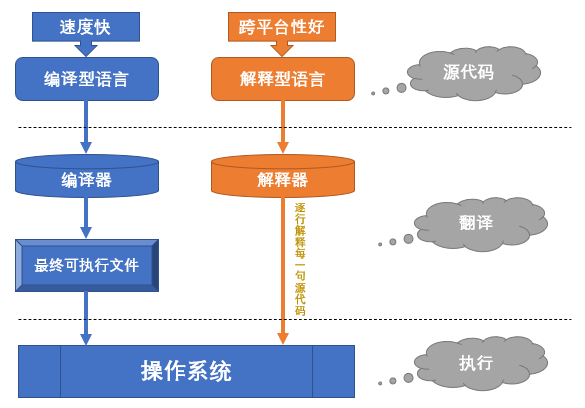
而 JavaScript 就是一种解释型脚本语言,支持动态类型、弱类型、基于原型的语言,内置支持类型。鉴于 JavaScript 都是在前端执行,而且需要及时响应用户,这就要求 JavaScript 可以快速的解析及执行。V8 引擎使 JavaScript 的性能的得到了大幅度的提升,下面就来深入理解大名鼎鼎的 V8 引擎吧!
# 二、认识 V8 引擎
看到 V8 这个词,我们可能会联想到发动机,因为 V8、V10、V12 发动机这种概念可能都有所耳闻,的确,V8 的名字正是来源于汽车的 V 型 8 缸发动机,因为马力十足而广为人知,V8 引擎的命名是 Google 向用户展示它是一款强力并且高速的 JavaScript 引擎。
V8 引擎是一个 JavaScript 引擎实现,最初由一些语言方面专家设计,后被谷歌收购,随后谷歌对其进行了开源。V8 使用C++开发,,在运行 JavaScript 之前,相比其它的 JavaScript 的引擎转换成字节码或解释执行,V8 将其编译成原生机器码(IA-32, x86-64, ARM, or MIPS CPUs),并且使用了如内联缓存(inline caching)等方法来提高性能。有了这些功能,JavaScript 程序在 V8 引擎下的运行速度媲美二进制程序。V8 支持众多操作系统,如 windows、linux、android 等,也支持其他硬件架构,如 IA32,X64,ARM 等。 V8 可以独立运行,也可以嵌入到任何 C++应用程序中 ,具有很好的可移植和跨平台特性例如大名鼎鼎的 Node.js 就嵌入了 V8 引擎。
# 三、V8 引擎架构及执行流程
# 🥀 早期的 V8 引擎架构模式
V8 引擎的诞生带着使命而来,就是要在速度和内存回收上进行革命的。JavaScriptCore 的架构是采用生成字节码的方式,然后执行字节码。Google 觉得 JavaScriptCore 这套架构不行,生成字节码会浪费时间 ,不如直接生成机器码快。所以 V8 在前期的架构设计上是非常激进的, 采用了直接编译成机器码的方式 。后期的实践证明 Google 的这套架构速度是有改善, 但是同时也造成了内存消耗问题 。可以看下 V8 的初期流程图:
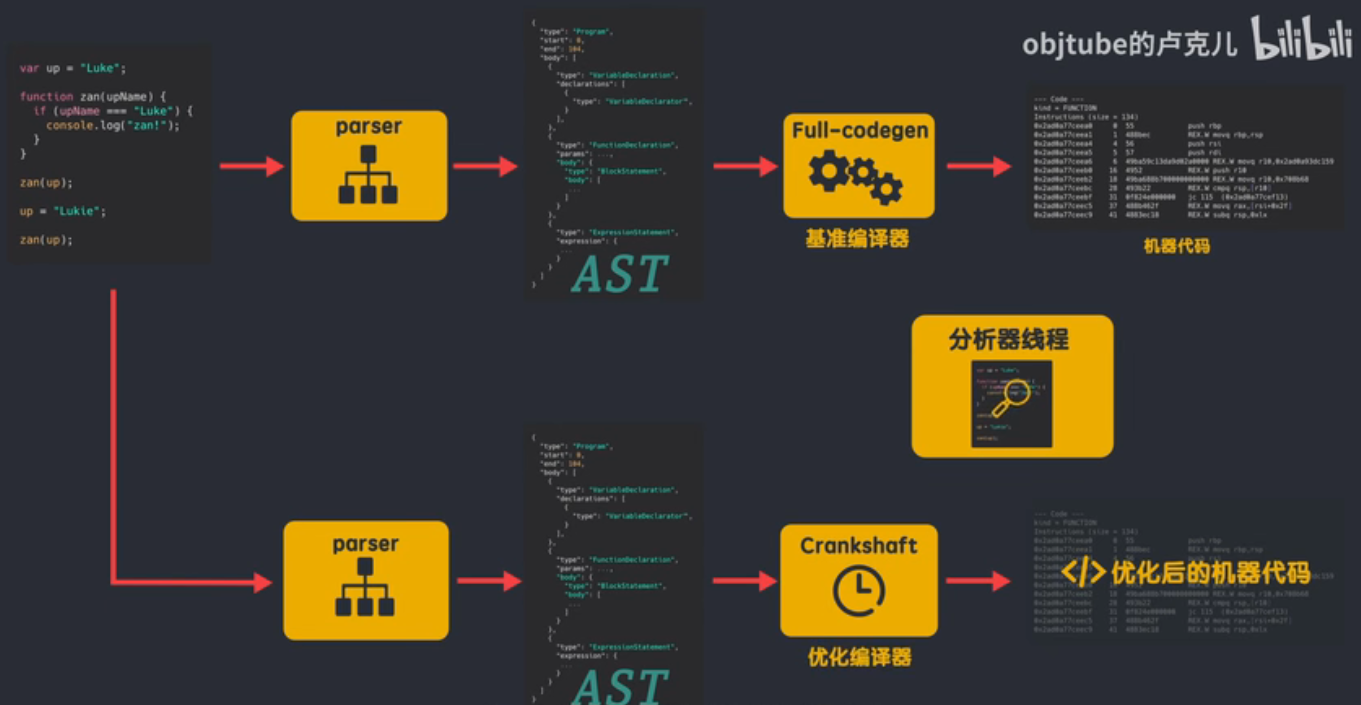
早期的 V8 有Full-Codegen和Crankshaft两个编译器。V8 首先用 Full-Codegen 把所有的代码都编译一次,生成对应的机器码。JS 在执行的过程中,V8 内置的 Profiler 筛选出热点函数并且记录参数的反馈类型,然后交给 Crankshaft 来进行优化。所以 Full-Codegen 本质上是生成的是未优化的机器码,而 Crankshaft 生成的是优化过的机器码。
随着版本的引进,网页的复杂化,V8 也渐渐的暴露出了自己架构上的缺陷:
Full-Codegen编译直接生成机器码,导致内存占用大Full-Codegen编译直接生成机器码,导致编译时间长,导致启动速度慢Crankshaft无法优化 try,catch 和 finally 等关键字划分的代码块Crankshaft新加语法支持,需要为此编写适配不同的 Cpu 架构代码
# 🌼 现在的 V8 引擎架构
为了解决上述缺点,V8 采用 JavaScriptCore 的架构,生成字节码。下面将展开讲述现在 V8 引擎架构及执行机制。
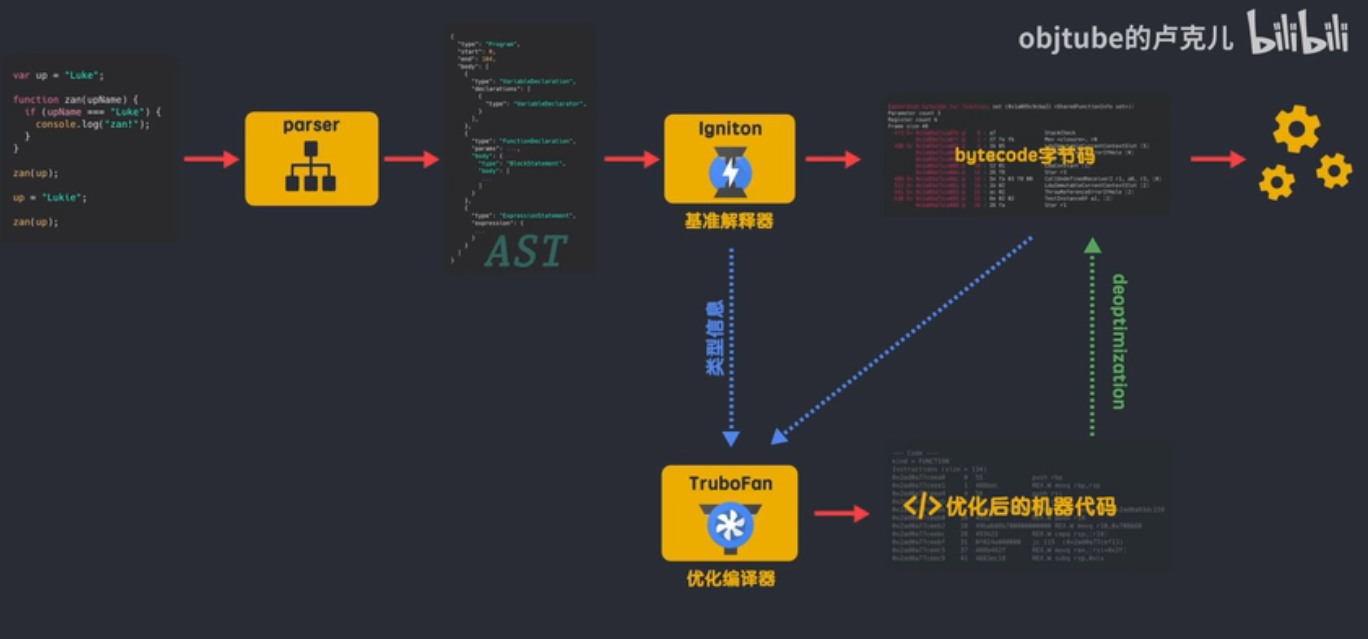
在开始之前,我们先来简单的了解一下 V8 解析 JavaScript 的过程分为哪些步骤,这样我们可以在全局上对 V8 的整个执行流程有一个比较清晰的认识,简单来说,有以下几个步骤
- 预解析,检查语法错误但不生成
AST - 生成
AST,经过词法/语法分析,生成抽象语法树 - 生成字节码,基准解析器(
Ignition)将AST转换成字节码 - 生成机器码,优化编译器(
Turbofan)将字节码转换成优化过的机器码,此外在逐行执行字节码的过程中,如果一段代码经常被执行,那么V8会将这段代码直接转换成机器码保存起来,下一次执行就不必经过字节码,优化了执行速度。
# 🌹 1. 生产抽象语法树
高级语言是开发者可以理解的语言,但是让编译器或者解释器来理解就非常困难了。对于编译器或者解释器来说,它们可以理解的就是 AST 了。所以无论你使用的是解释型语言还是编译型语言,在编译过程中,它们都会生成一个 AST。这和渲染引擎将 HTML 格式文件转换为计算机可以理解的 DOM 树的情况类似。
生成 AST 需要经过两个阶段:
- 「第一阶段是分词(tokenize),又称为
词法分析」:把源码的字符串分割出来,生成一系列的Token,所谓 token,指的是语法上不可能再分的、最小的单个字符或字符串。
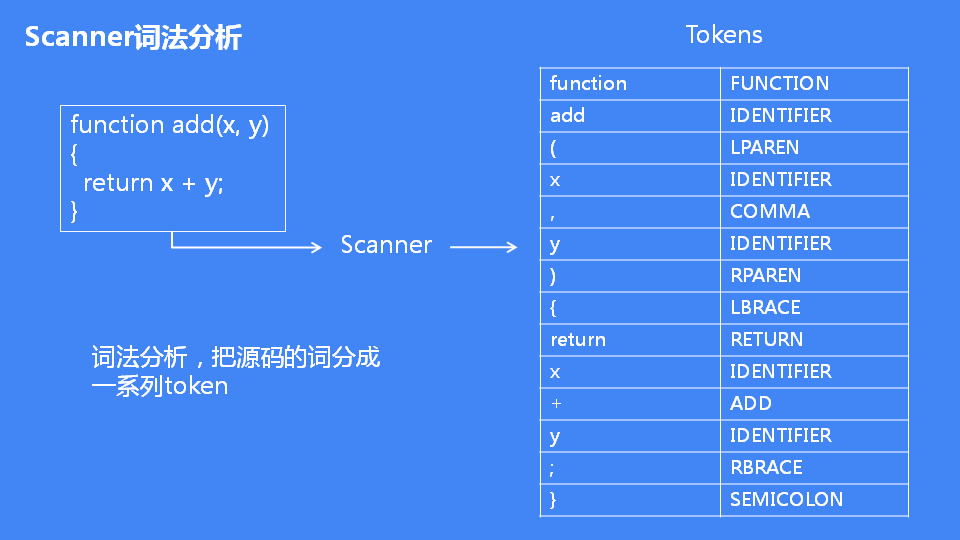
「第二阶段是解析(parse),又称为
语法分析,其作用是将上一步生成的 token 数据」,根据语法规则转为 AST。如果源码符合语法规则,这一步就会顺利完成。但如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。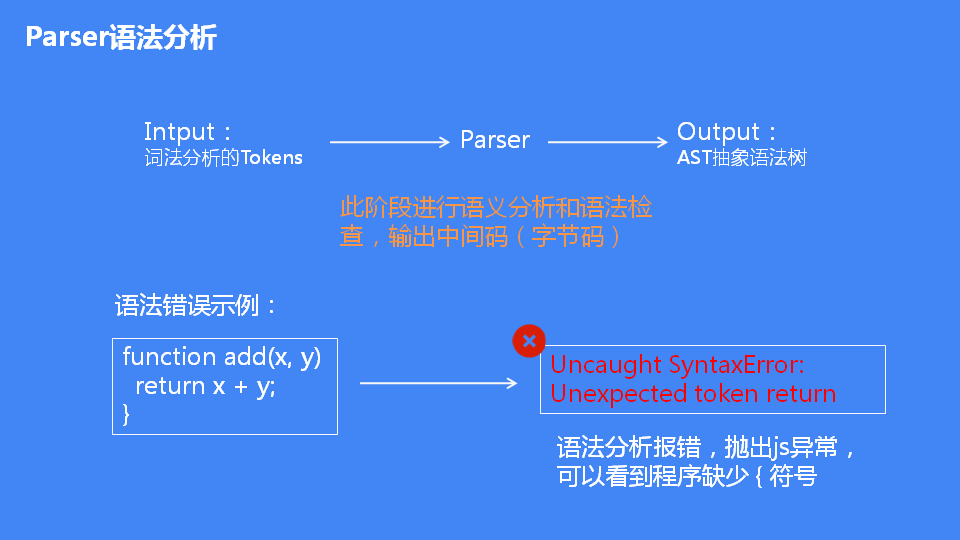
但是解析代码需要时间,所以 JavaScript 引擎会 尽可能避免完全解析源代码文件 ,而另一方面又因为在一次用户访问中,页面中会有很多代码其实是不会被执行到的,比如一些通过用户交互行为触发的动作,正因为如此,所有主流浏览器都实现了惰性解析(Lazy Parsing),解析器不必为每个函数生成 AST,而是可以决定预解析(pre-parsing)或完全解析它所遇到的函数,预解析会检查源代码的语法并抛出语法错误,但不会解析函数中变量的作用域或生成 AST,完全解析则将分析函数体并生成源代码对应的 AST 数据结构,相比正常解析,预解析的速度快了两倍。
AST Explorer 该工具可以帮助我们查看 JavaScript 代码被解析成 AST 的结果。
# 🌻 2. 生成字节码
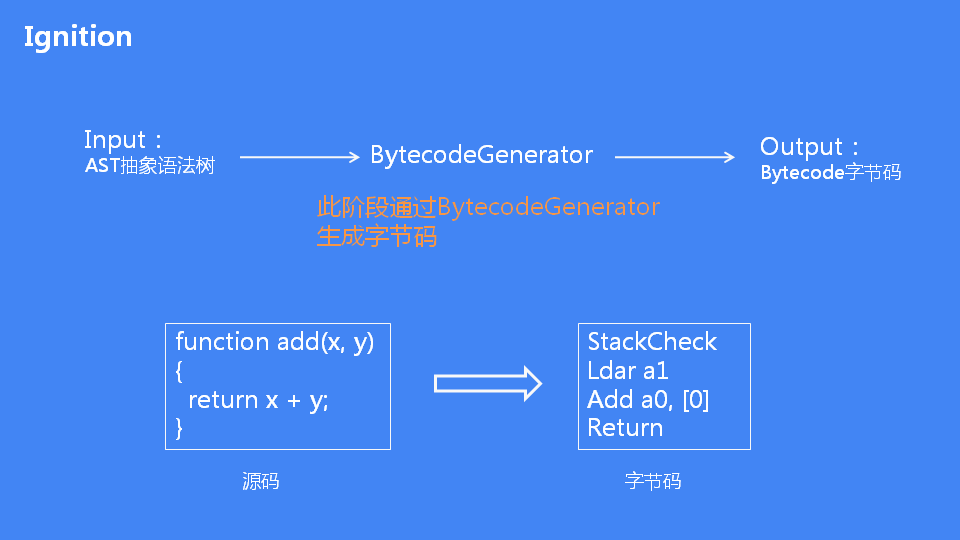
# 基准解释器 Ignition
有了 AST 后,接下来基准解释器 (Ignition) 就登场了,它会根据 AST 生成字节码,并解释执行字节码。「字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。」 机器码所占用的空间远远超过了字节码 ,所以使用字节码可以减少系统的内存使用。
# 优化编译器 TurboFan
编译器需要考虑的函数输入类型变化越少,生成的代码就越小、越快,众所周知,JavaScript 是弱类型语言,ECMAScript 标准中有大量的多义性和类型判断,因此通过基线编译器生成的代码执行效率低下。
Turbofan是根据字节码和热点函数反馈类型生成优化后的机器码,Turbofan 很多优化过程,基本和编译原理的后端优化差不多,采用的sea-of-node
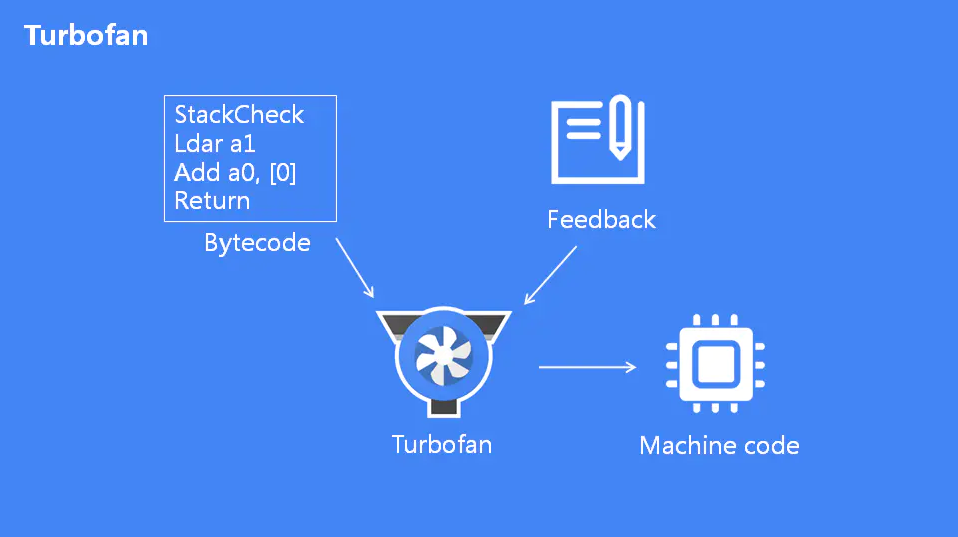
比如我们针对之前提到的 add 函数优化
function add(x, y) {
return x + y;
}
add(1, 2);
%OptimizeFunctionOnNextCall(add);
V8 是有函数可以直接调用指定优化哪个函数,执行 %OptimizeFunctionOnNextCall 主动调用 Turbofan 优化 add 函数,根据上次调用的参数反馈优化 add 函数,很明显这次的反馈是整型数,所以 turbofan 会根据参数是整型数进行优化直接生成机器码,下次函数调用直接调用优化好的机器码
注意执行
V8需要加上--allow-natives-syntax,OptimizeFunctionOnNextCall为内置函数,只有加上--allow-natives-syntax,JavaScript才能调用内置函数,否则执行会报错
JavaScript 的 add 函数生成对应的机器码如下

如果把 add 函数的传入参数改成字符
function add(x, y) {
return x + y;
}
add("1", "2");
%OptimizeFunctionOnNextCall(add);
优化后的 add 函数生成对应的机器码如下

对比上面两图可以发现,add 函数传入不同的参数,经过优化生成不同的机器码
- 如果传入的是整型,则本质上是直接调用
add汇编指令 - 如果传入的是字符串,则本质上是调用
V8的内置Add函数
# 🌷 3. 执行代码
通常,如果有一段第一次执行的字节码,解释器 Ignition 会逐条解释执行。到了这里,相信你已经发现了, 解释器 Ignition 除了负责生成字节码之外,它还有另外一个作用,就是解释执行字节码 。在 Ignition 执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为**「热点代码」**,那么后台的编译器 TurboFan 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。
字节码配合解释器和编译器是最近一段时间很火的技术,比如 Java 和 Python 的虚拟机也都是基于这种技术实现的,我们把这种技术称为「即时编译(JIT)」。具体到 V8,就是指解释器 Ignition在解释执行字节码的同时,收集代码信息,当它发现某一部分代码变热了之后,TurboFan 编译器便闪亮登场,把热点的字节码转换为机器码,并把转换后的机器码保存起来,以备下次使用。